年前看过一遍kafka的文档,没想到现在忘得差不多了,于是结合自己的理解来写一篇译文。
简介
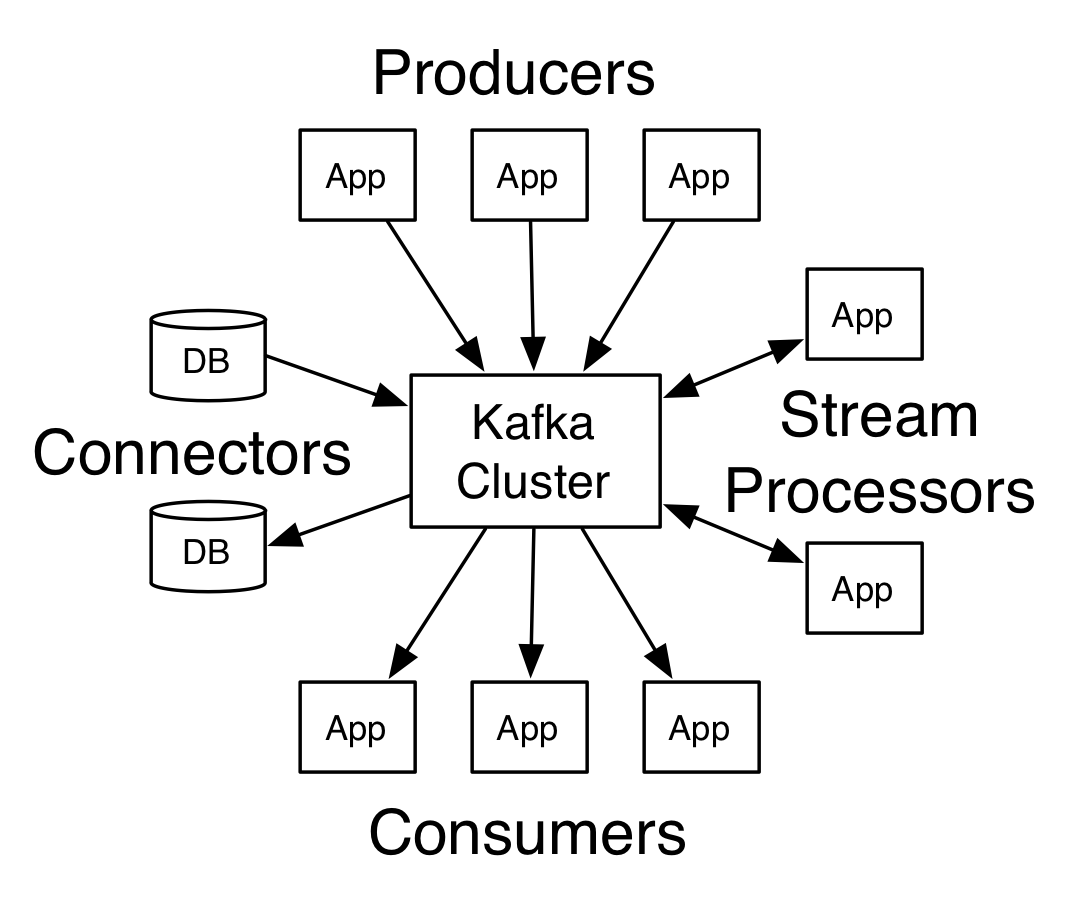
kafka是一个分布式流处理平台
有三个关键特性
- 发布、订阅,类似消息队列
- 错误容忍的持久化流数据
- 处理流式数据
kafka有两个比较大的应用场景
- 构建实时流数据管道(偏向于数据传输)
- 构建实时流数据处理(根据数据做出对应的行为)
概念
- kafka以集群运行,支持跨dc部署
- kafka集群分类存储流数据,叫做topic
- 每条记录都包含key、value、timestamp
kafaka有四大核心API
- Producer
- Consumer
- Stream(流数据处理)
- Connector(和现有系统的集成)
Topics and Logs
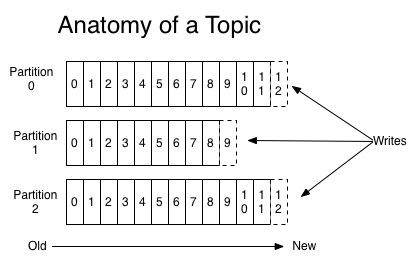
一个topic包含多个partition,partition内部的数据是有序并且不可变的。向kafka写入数据,其实就是在向某个partition追加数据。kafka只保证单个partition内的数据是有序的!
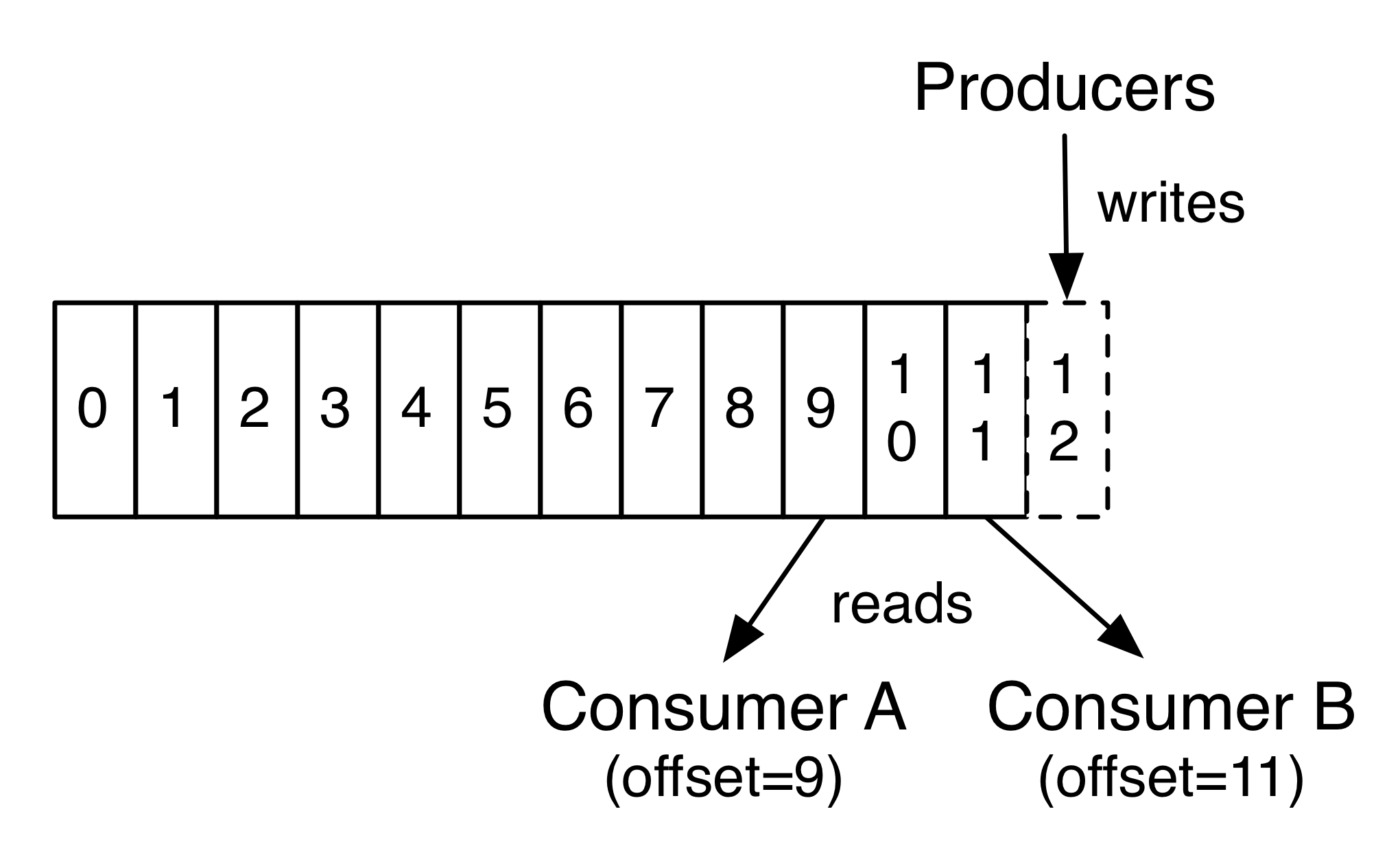
而消费时,客户端其实就是在控制partition内部的指针。
kafka会在一个可配置的周期内,保存所有消息(无论有没有被消费)
Distribution
topic内的partitions会分布在多台server上,但partition本身不可再分。为了防止partition挂了丢失数据,partition本身也会有主从备份机制,leader处理所有读写,follower复制leader作为备份。
在宏观上,每台物理服务器会包含多个不同topic的partition,其中一部分是leader partition,一部分是follower partition,通过这样来均衡集群内的负载
Geo-Replication
提供了跨dc的复制机制,我觉得99%的企业用不上这个特性。
Producers
负责向topic发送数据,它需要通过一些策略来选择topic内的某个partition进行写入,
Consumers
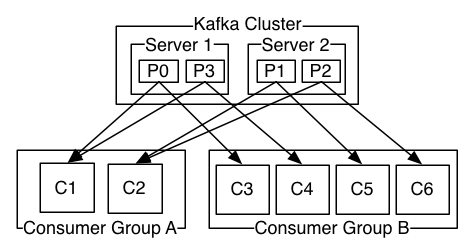
kafka里的consumer有点特殊,它们会组成一个叫consumer group的概念,投递给topic的消息,最终会被订阅这个topic的consumer group中的某一个consumer消费。可以理解成,消息会被传递给consumer group,然后group内部通过某种策略选择具体的consumer处理。consumer可以分布于不同的进程或者机器上。
如果订阅某个topic的所有consumer都属于同一个group,那么消息会被高效地负载均衡。
如果订阅某个topic的所有consumer都属于不同的组,那么消息会被广播给所有的consumer
Guarantees
kafka提供的保证有三点
- 同一个producer向同一个partition发送的数据是有序的
- consumer看到的数据是有序的(即数据被存储的顺序)
- topic有N个备份,能保证在N-1个server当机时不丢失数据。
优势
传统消息队列的queue和pub\sub模型,都有不足之处。
queue不支持多个subsriber,某个subsriber读了数据,这个数据就没了
pub\sub无法扩展处理能力,因为每个消息都会投递给所有subsriber
kafka以consumer group作为订阅的单位,就解决了这两个模型的不足。
kafka还是可靠又快速的存储系统,性能几乎不受数据量的影响。